
Known as SurfNet, the program could have applications in robotics and autonomous vehicles, as well as content creation for the emerging 3D industry. It works by mapping 2D images onto a 3D sphere, then opening up that sphere to create a new 2D shape.
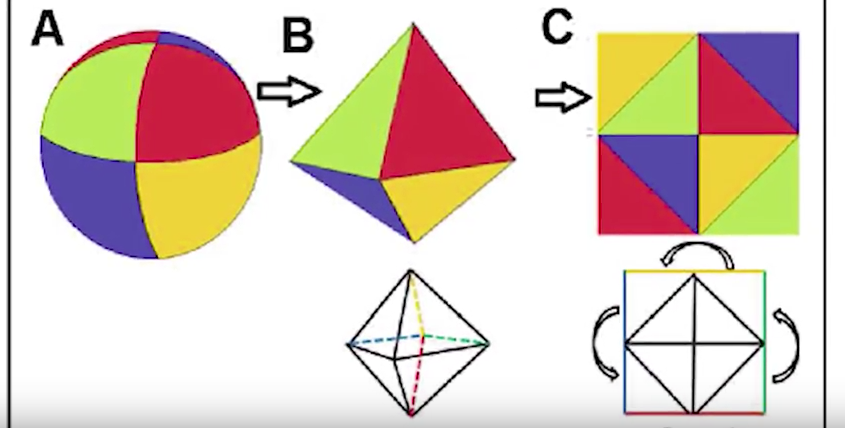
SurfNet then applies that technique to huge numbers of 2D images, learning abstractly via machine and deep learning. The system learns the 3D image and the 2D image in pairs, and this enables it to predict other, similar 3D shapes from just a 2D image.
"If you show it hundreds of thousands of shapes of something such as a car, if you then show it a 2D image of a car, it can reconstruct that model in 3D," said Karthik Ramani, Purdue's Donald W Feddersen Professor of Mechanical Engineering
"It can even take two 2D images and create a 3D shape between the two, which we call 'hallucination.'"
According to Ramani, the technique allows for greater accuracy and precision than current 3D deep learning methods that use volumetric pixels, or voxels.
"We use the surfaces instead since it fully defines the shape,” he explained. “It's kind of an interesting offshoot of this method. Because we are working in the 2D domain to reconstruct the 3D structure, instead of doing 1,000 data points like you would otherwise with other emerging methods, we can do 10,000 points. We are more efficient and compact."
"This is very similar to how a camera or scanner uses just three colours, red, green and blue—known as RGB—to create a colour image, except we use the XYZ coordinates."
As the program improves, the researchers hope it can be used to create 3D content using non-specialist 2D equipment, and also allow machines to understand 3D environments from simple 2D images.
Swiss geoengineering start-up targets methane removal
No mention whatsoever about the effect of increased methane levels/iron chloride in the ocean on the pH and chemical properties of the ocean - are we...