AI program coverts 2D into 3D
Researchers at Purdue University have developed a new program that uses artificial intelligence to transform 2D images into 3D shapes.

Known as SurfNet, the program could have applications in robotics and autonomous vehicles, as well as content creation for the emerging 3D industry. It works by mapping 2D images onto a 3D sphere, then opening up that sphere to create a new 2D shape.
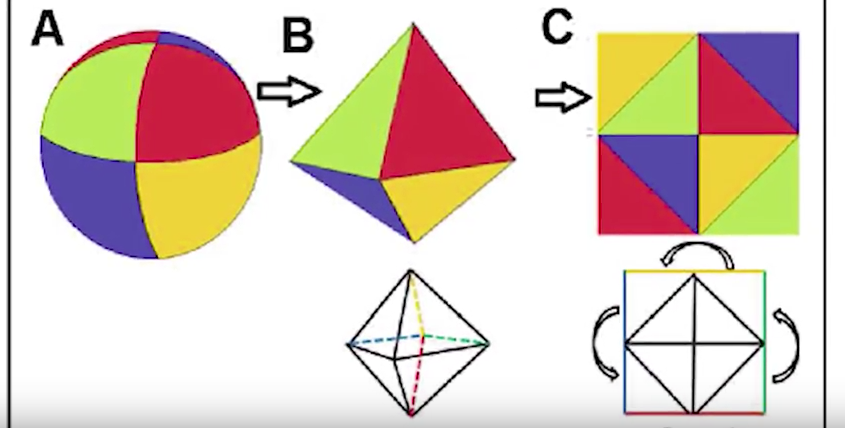
SurfNet then applies that technique to huge numbers of 2D images, learning abstractly via machine and deep learning. The system learns the 3D image and the 2D image in pairs, and this enables it to predict other, similar 3D shapes from just a 2D image.
"If you show it hundreds of thousands of shapes of something such as a car, if you then show it a 2D image of a car, it can reconstruct that model in 3D," said Karthik Ramani, Purdue's Donald W Feddersen Professor of Mechanical Engineering
"It can even take two 2D images and create a 3D shape between the two, which we call 'hallucination.'"
Register now to continue reading
Thanks for visiting The Engineer. You’ve now reached your monthly limit of news stories. Register for free to unlock unlimited access to all of our news coverage, as well as premium content including opinion, in-depth features and special reports.
Benefits of registering
-
In-depth insights and coverage of key emerging trends
-
Unrestricted access to special reports throughout the year
-
Daily technology news delivered straight to your inbox



Water Sector Talent Exodus Could Cripple The Sector
Maybe if things are essential for the running of a country and we want to pay a fair price we should be running these utilities on a not for profit...