Engineers are increasingly looking to integrate AI into projects and applications while attempting to climb their own AI learning curve. To tackle AI, engineers should start with understanding what AI is and how it fits into their current workflow, which might not be as straightforward as it seems. A simple search of “What is AI?” yields millions of results on Google, with varying degrees of technical and relevant information.
So, what is AI to engineers?
Most of the focus on AI is all about the AI model, which drives engineers to quickly dive into the modelling aspect of AI. After a few starter projects, engineers learn that AI is not just modelling, but rather a complete set of steps that includes data preparation, modelling, simulation and test, and deployment.
MORE ON ARTIFICIAL INTELLIGENCE
Most often, AI is only a small piece of a larger system, and it needs to work correctly in all scenarios with other components of the end product, including sensors and algorithms such as control, signal processing, and sensor fusion. Engineers in these scenarios often already have the skills to be successful incorporating AI into their product. They have inherent knowledge about the problem, and with tools for data preparation and designing models, they can get started even if they’re not AI experts, allowing them to leverage their existing areas of expertise.
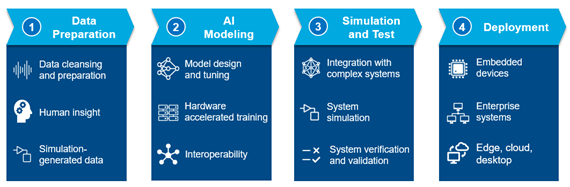
There are four steps for the AI-driven complete workflow that each play their own critical role in successfully implementing AI into a project.
Step 1: Data Preparation
Data preparation is arguably the most important step in the AI workflow. Without robust and accurate data as input to train a model, projects are more likely to fail. If an engineer gives the model “bad” data, they will not get insightful results—and will likely spend many hours trying to figure out why the model is not working.
To train a model, you should begin with as much clean, labelled data, as you can gather. This may be one of the most time-consuming steps of the workflow. When deep learning models do not work as expected, many often focus on how to make the model better—tweaking parameters, fine-tuning the model, and multiple training iterations. However, engineers would be better served focusing on the input data: pre-processing and ensuring correct labelling of the data being fed into a model to ensure that the model can learn from the data.
Automatic labelling and integration are now possible and critical to efficiently completing the first step. We developed tools in MATLAB to quickly clean and labelled data for input into machine learning models, providing more promising insights from field machinery. The process is scalable and gives users the flexibility to use their domain expertise without having to become experts in AI.

Step 2: AI Modelling
After the data is clean and properly labelled, it’s time to move on to the modelling stage of the workflow, which is where data is used as input, and the model learns from that data. The goal of a successful modelling stage is to create a robust, accurate model that can make intelligent decisions based on the data – and critically, on new unseen data. AI models can use deep learning (neural networks), machine learning (SVM, decision trees, etc.), or a combination of the two, as engineers search for the most accurate, robust result. Deep learning is a branch of machine learning that teaches computers to do what comes naturally to humans: learn from experience. Machine learning algorithms use computational methods to “learn” information directly from data without relying on a predetermined equation as a model. Deep learning is a subset of machine learning that uses a layered structure of algorithms called neural networks. They can be very powerful but often require huge amounts of data. The choice between machine learning or deep learning depends on your data and the problem you’re trying to solve.
At this stage, regardless of deciding between deep learning (neural networks) or machine learning models (SVM, decision trees, etc.), it’s important to access the many algorithms used for AI workflows, such as classification, prediction, and regression. You may also want to use a variety of prebuilt models developed by the broader community as a starting point or for comparison. It can really kick-start the work to start with existing similar models. Deep learning is especially suited for image recognition, which is important for solving problems such as facial recognition, motion detection, and many advanced driver assistance technologies such as autonomous driving, lane detection, pedestrian detection, and autonomous parking.
AI modelling is an iterative step within the complete workflow, and engineers must track the changes they are making to the model throughout this step. Tracking changes and recording training iterations is crucial as it helps the engineer explain the parameters that lead to the most accurate model and create reproducible results.

Step 3: Simulation and Test
AI models exist within a larger system and must work with all other pieces in the system. Consider an automated driving scenario: You start with a perception system for detecting objects (pedestrians, cars, stop signs), but this must also integrate with other systems for localisation, path planning, controls, and more. Simulation and testing for accuracy are key to validating that the AI model is working properly, and everything works well together with other systems, before deploying a model into the real world.
Trust is achieved after you have successfully simulated and tested all cases you expect the model to see and can verify that the model performs on target. We created tools in Simulink to allow engineers to verify that the model works as desired for all the anticipated use cases, avoiding redesigns that are costly both in money and time.
Step 4: Deployment
Once you are ready to deploy, the target hardware is next—in other words, readying the model in the final language in which it will be implemented. This step typically requires design engineers to share an implementation-ready model, allowing them to fit that model into the designated hardware environment.
By following these four steps, engineers will set themselves up for success. Taking advantage of the tools and aid available to them will help them navigate what can be an intimidating environment.



Water Sector Talent Exodus Could Cripple The Sector
Maybe if things are essential for the running of a country and we want to pay a fair price we should be running these utilities on a not for profit...